Reinforcement Learning Queue Control
Reinforcement learning is characterized by the learning problem and not by any specific method. A challenge in reinforcement learning is balancing exploration and exploitation (Sutton & Barto, 2012). Reinforcement learning systems have a policy, a reward function for short term goals, a value function for long term goals, and typically a model of the environment (Sutton & Barto, 2012).
Queue Control System
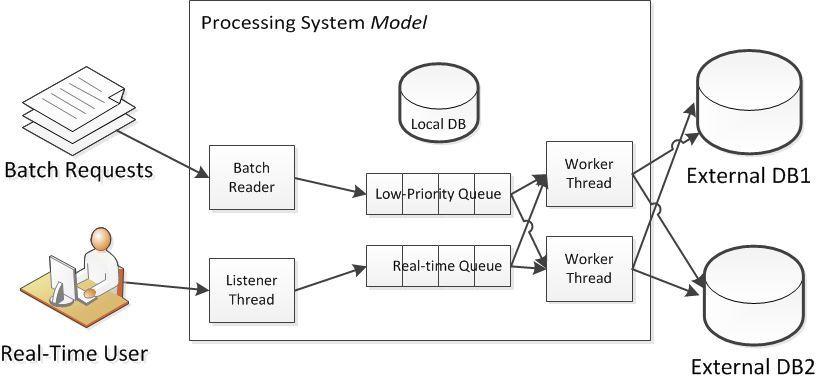
The system under consideration is the controlling of queues. To elaborate on this problem further, the system model has high priority transactions which must be completed in “real-time” as a human user is directly waiting for them. These are typically during the day and tend to be done in “bursts”. Another class of transactions can be done in the background; those are commonly referred to as batch transactions There is a large supply of batch transactions to occupy idle periods.
For short term and long term goals, there is a reward function and a value function respectively (Sutton & Barto, 2012). The long-term goal is to maximize the entire throughput of the system. The value function is the count of successful completed transactions per day. The short-term goal is that “real-time” transactions must be completed within a short service-level agreement time frame without errors. In this sense, the rewards are lack of negative penalties for timeouts or errors.
What makes this problem difficult is the complexity of the environment which depends upon shared resources. For example, there is a local database and there are external databases. There is a random confounding factor in which the external databases have competing demands placed upon them by other systems. The transactions running through the system are not identical. Some transactions are rather complex and hit many external databases as well as the local database.
The parts that need optimization is the queue control agent with the number of workers. If too few workers are allocated, then overall transaction times will increase due to a backlog. If too many workers are created, then overall transaction times increase due to contention (both externally and internally). The number of workers must change given the demands on the system as well as the unknown demands placed upon the external databases.
A challenge in reinforcement learning is the challenge in balancing exploration and exploitation. To get a reward, the system must exploit something learned but to get better rewards, it needs to explore. In this problem, the system at times must “hire” another worker thread to attempt to run more transactions to determine if there is additional available bandwidth.
This becomes an optimization problem that is dynamic. What may have been optimal an hour ago might not be optimal now given the other random processes that are not visible to the system. In other words, those databases might be bogged down. Placing an undue load up on a database will cause a nonlinear response to happen. When the database is bogged down, execution time grows exponentially.
Temporal-Difference Learning
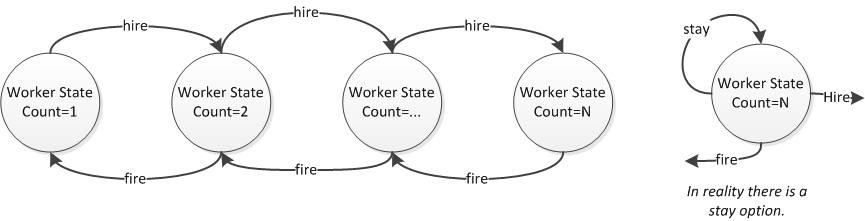
An approach to formalize this is to utilize Temporal-Difference Learning methodology (Sutton & Barto, 2012) by treating each worker count as a state. Each state would maintain estimations as suggested by Abbeel (n.d.) of transaction times and potential errors. The learning rate for the two models types could be chosen to allow the models to slowly forget very old data to adapt to new circumstances as well as convergence. The “value” function is the count of successful transactions completed per day and the “reward” function is a penalty in this use-case as it the count of errors.
# Logic Based on Temporal Differencing Let V[s] be an list of states. Initialization s=1. #We will start with 1 worker. alpha <- 0.05 #learning rate Repeat if both queues are empty then wait idle if real-time queue is not empty then t <- pull transaction from real-time queue else if batch queue is not empty then t <- pull transaction from batch queue time <- how long to perform transaction t V[s].count <- V[s].count + 1 # count-error is the "value function" if error then V[s].error <- V[s].error + 1 # errors are "anti-reward" V[s].meanTime <- (1.0 - alpha) * V[s].meanTime + alpha*time give back completed transaction #explore logic if random > (V[s+1].count+1)/(V[s+1].count+2) then s = s + 1; #hire another worker else if random > (V[s-1].count+1)/(V[s+1].count+2) then s = s - 1; #fire worker #exploit logic len = length of real-time queue if( s>1 #we do not want to fire all workers and (len * V[s].meanTime )/s > (len * V[s-1].meanTime )/(s-1) #will the timings improve? and V[s].error/V[s].count <= V[s-1].error/V[s-1].count ) #we must maintain low errors then s = s - 1; #fire worker if( (len * V[s].meanTime )/s > (len * V[s+1].meanTime )/(s+1) #will the timings improve? and V[s].error/V[s].count <= V[s+1].error/V[s+1].count ) ) #we must maintain low errors then s = s + 1; #hire worker #otherwise keep worker count until day is done |
For more advanced logic with additional predictor variables, Arel (2015) hints that each state could contain an “online” Bayesian prediction model, which could be used for transaction failures. An “online” stochastic gradient-descent model for transaction times as suggested by Sutton and Barto (2012) could be utilized including additional factors such as hour of the day.
Conclusion
Using the approaches as outlined by the referenced readings, one could implement such a system and the system would adapt to ongoing changes. It would be self-tuning and require no administration once installed. Reinforcement Learning techniques offer an exciting way to assemble machine learning into a framework for solving problems that are ever changing.
References
Abbeel, P. (n.d.) CS 188: Artificial intelligence reinforcement learning (RL). UC Berkeley. Retrieved from: https://inst.eecs.berkeley.edu/~cs188/sp12/slides/cs188%20lecture%2010%20and%2011%20–%20reinforcement%20learning%202PP.pdf
Arel, I. (2015) Reinforcement Learning in Artificial Intelligence. Retrieved from: http://web.eecs.utk.edu/~itamar/courses/ECE-517/notes/lecture1.pdf
Sutton, R. S. & Barto, A. G. (2012) Reinforcement Learning. MIT Press.