Study Habits with Model Devices Best Practice
by Christopher G. Busch
Abstract
Today’s freshmen students have been called “digital natives” (Brännback, Nikou, & Bouwman, 2016). However, students bring with them varying levels of digital skills, some useful pedagogically and some not since there exists outcomes gaps (Adhikari, Mathrani, & Parsons, 2015). Self-directed learning on behalf of the student via mobile devices supports learners to gain intellectual and social advantages in the learning sphere (Kong & Song, 2015). There is no clear best practice for BYOD mobile device educational usage to help freshmen. Therefore, proposed is a study to gather and share BYOD best practice to give freshmen the digital mobile device study skills they need. At the beginning and end of the freshman year, all freshman students will be surveyed to measure experience and self-reported improvement in study habits skill level with mobile devices. This research will not only determine the best skills; it will also show the importance of sharing those skills with students to empower them.
Keywords: BYOD, freshmen
Introduction
Bring your own device (BYOD) is the idea that one brings a personal mobile device into an environment to gain greater success. Mobile devices provide affordances for learning support (Kong & Song, 2015). Students who enhance their studies through self-study may be facilitated by their own mobile devices (Kong & Song, 2015). Today’s freshmen students have been called “digital natives” (Brännback, Nikou, & Bouwman, 2016). However, students bring with them varying levels of digital skills, some useful pedagogically and some not. This proposal attempts to identify those mobile device practices that are most effective to increasing mobile device based study habits skill level. Surveys will be conducted to measure the effectiveness of those practices.
Domain and Context
Mobile devices are so prevalent in our society that we may take them for granted. However, all freshmen students might not possess necessary mobile device study habits skill for a variety of reasons. Those reasons are categorized into three “digital divides”: access, capability, and outcome (Wei, Teo, Chan, & Tan, 2011). An outcome divide exists which originates from a capability divide (Adhikari, Mathrani, & Parsons, 2015). That capability divide may arise from lack of understanding and access to mobile devices (Adhikari et al., 2015). Access gaps due to affordability of devices and poor connectivity exist (Adhikari et al., 2015). The lack of digital skills may heighten disparities in freshman college experience with a resulting outcome gap.
Research Problem and Questions

The process for the study is based on the Design Science Research Methodology (DSRM) (Peffers, Tuunanen, Rothenberger, & Chatterjee, 2008). The authors explain the process as an iterative six step process that can begin at any of the first four steps of the process. The six steps are as follows: problem identification, objective definition, design & development, demonstration, evaluation, and communication (Peffers, Tuunanen, Rothenberger, & Chatterjee, 2008). In this study, the problem is a lack of clearly defined best practice for mobile device usage for freshmen students. The objective is to share BYOD best practice to give freshmen the digital mobile device study skills they need. To set a baseline for evaluation, at the beginning of the year, incoming freshmen students will be surveyed to measure study habits and self-reported skill levels. A student focus group will convene to design and develop the mobile device study habits best practice with guidance from faculty with the results distributed to students for them to take up and demonstrate. At the end of the freshman year to evaluate the study, all freshman students will be surveyed again to measure experience and self-reported improvement in study habits skill level with mobile devices. This research will document to communicate the best practice and the effectiveness with the freshmen students and eventually throughout greater academia.
The study seeks to answer these questions. (1) What is the general study habits skill-level of incoming freshmen students? (2) Is there best practice for BYOD usage that can be shared to all incoming freshman students that can give them the digital mobile device study skills they need? (3) Once compiled and distributed to students, do students readily pick up those shared best practices?
Rationale and Literature Review
The rationale for the study is underscored by the many studies that have suggested that BYOD mobile device initiatives are beneficial and that there are gaps in students’ mobile device study habits. No formally defined best practice has been documented although researchers encourage to undertake such an endeavor.
Gaps
The Adhikari, Mathrani, and Parsons (2015) study investigated how the introduction of BYOD based education has changed digital divides and it evaluated the effectiveness of the BYOD initiative. The authors use a digital divide concept as a framework for their study consisting of: access, capability, and outcome (Adhikari et al., 2015). Those divides can have undue effect on the learning process.
The good news regarding access gaps among students is the findings that less than 5% lack access to mobile devices (Farley et al., 2015). Of those who have access, over 96% of the students have a very capable operating system as part of their smart phone (Farley et al., 2015). Overall, a high percentage of students (87%) support using mobile devices to enhance their learning (Farley et al., 2015).
Capability and outcome gaps may originate from lack of knowledge of proper mobile device usage patterns. The Parsons and Adhikari (2016) study points out that the students perceive their digital skills as advancing rapidly when using mobile devices, however, instructors interpret the development with more scrutiny. The teaching staff note the actual classroom use of digital devices requires more attention. One interesting finding is that younger university students are more concerned with device distraction while older students stated at the devices were not a distraction (Gikas & Grant, 2013). Presumably, the sharing of mobile device best practice could assist students who may have less experience with mobile devices. The focus group will need to address the concerns for the devices to distract students (Farley et al., 2015).
As for frustrations, the students noted several and difficulties are not only for students. Gikas and Grant (2013) explain that different universities encourage instructors to utilize computing devices but with varying levels of support. However, some instructors at the universities deemed mobile devices inappropriate which causes barriers. Furthermore, Al-Emran, Elsherif, and Shallan (2016) could not find a demographic reason for instructor attitudes concerning mobile devices. Overall, teaching staff have struggled to fully learn their digital skills in the education environment (Adhikari et al., 2015). Students are frustrated with those instructors who have an anti-technology view in the way the classes were given. Another area of frustration is device challenges with the quality of some of the software which required workarounds or different applications entirely (Gikas & Grant, 2013).
Digital Community of Learning
A high percentage of university students (87%) support using mobile devices to enhance their learning (Farley et al., 2015). A BYOD initiative will have at least a small positive trend for increased educational use of the devices (Adhikari et al., 2015).
Kong and Song (2015) emphasize that BYOD initiatives increase learning interactions with peers and teachers, anytime and anywhere. In this way, both formal and informal learning opportunities are enhanced (Gikas & Grant, 2013). Parsons and Adhikari (2016) note that this develops collaborative cultural practices which is one of the most important benefits of a mobile device initiative. As an example of cultural practice with informal learning, university students developed back channel discussion groups, such as a Twitter based “Tweet-a-thon” (Gikas & Grant, 2013, p. 22). As for formal learning methods, students at Coastal College utilized video sharing services to collect data and interact with faculty and fellow students as part of a class assignment (Gikas & Grant, 2013).
Farley et al. (2015) encourage educators to include mobile devices for students to enhance their learning. Educators could use the results of the focus group to build curriculum utilizing the mobile devices. This acts on the suggestion of Adhikari et al. (2015) to look for educational approaches for maximization of knowledge acquisition and skill development. Frequently, such as in the Farley et al. (2015) study, no examples of educators utilized mobile learning in the school courses. However, when instructors begin utilizing BYOD mobile devices as part of the classroom, based on the quantitative results of the Parsons and Adhikari (2016) study, students and instructors report improvement on digital skills. The instructors’ responses are especially positive.
To support mobile devices, the Farley et al. (2015) study suggests that lectures and class materials be made available in a variety of formats such as podcasts. The school website should be mobile friendly and existing social media, such as Facebook, be utilized for students to congregate (Farley et al., 2015). Farley et al. (2015) suggest a mobile learning evaluation toolkit which is directly applicable to the focus group concept to be utilized by the proposed research. The Farley et al. (2015) study also recommends finding specific apps and resources that are mobile friendly. The objectives of the focus group are to determine the best practice for mobile device usage and therefore extends the concepts from Farley et al. (2015). The proposed study will need to follow those recommendations.
A curriculum format that embraces mobile devices is explained by Song and Kong. Song and Kong (2015) state that higher education needs to promote self-directed learning to stimulate and engage students. This engagement supports students to gain intellectual and social advantages (Kong & Song, 2015). They encourage higher education to promote reflective engagement of students to drive active learning. They define reflective engagement as active and continued participation on behalf of the students. Reflective engagement is self-directed learning which can stimulate a student. Reflective engagement on behalf of the student supports learners to gain intellectual and social advantages in the learning sphere (Kong & Song, 2015). That engagement framework encourages students to drive mobile interactions, assists teachers in designing an educational environment for learners (Kong & Song, 2015).
Song and Kong (2015) share insights from a BYOD initiative that focuses on learners’ reflective engagement in classrooms that use a flipped arrangement. A flipped classroom is one where students learn from lectures on videos outside of the classroom and do their “homework” inside the classroom (Song & Kong, 2015). Teaching staff should consider a flipped classroom strategy which could have a successful experience when it is integrated with a BYOD policy (Kong & Song, 2015).
Significance
The research will identify those practices of mobile device usage that positively affect student study habits skill level. The proposed study focuses on post-secondary freshmen students with guidance from faculty to arm them with the best practice to address learning and distraction burdens with mobile device study habits. As it relates to the new study, Kong and Song (2015) underscore the rationale of the study that higher education needs to promote self-directed learning to stimulate and engage students. This engagement supports students to gain intellectual and social advantages (Kong & Song, 2015). Student personal study habits are applicable to all coursework.
Conclusions
Mobile device self-study skills are vital and not universally known. Capability and outcome gaps exist in students from lack of knowledge of proper mobile device usage patterns. Mobile device digital self-study skills need to be discovered and shared to support pedagogical endeavors.
Students are eager to learn and adopt mobile device techniques. A high percentage of university students (87%) support enhancing their learning using mobile devices (Farley et al., 2015). Digital natives use of social media not as an end to a means but rather as a component to their lives (Brännback, Nikou, & Bouwman, 2016).
Collaborative cultural practices are at the cornerstone of the best practice for mobile device usage (Parsons & Adhikari, 2016). Gikas and Grant (2013) and Kong and Song (2015) stress the importance of facilitating collaboration, anytime and anywhere, between peers and teachers.
Knowledge of what works and which apps that do not, needs to be shared. Dedicated apps for educational community development are essential for maximizing engagement of students in educational endeavors. Farley et al. (2015) recommends finding apps and mobile friendly resources to develop techniques for mobile learning.
This study needs fulfill those recommendations by giving an actionable best practice that have been evaluated for effectiveness. This research is to determine the best mobile device study habits and show the importance of sharing those skills with students to empower them.
References
Adhikari, J., Mathrani, A., & Parsons, D. (2015). Bring your own devices classroom: Issues of digital divides in teaching and learning contexts. Australasian Conference on Information Systems. Retrieved from https://arxiv.org/ftp/arxiv/papers/1606/1606.02488.pdf
Al-Emran, M., Elsherif, H. M., Shallan, K. (2016) Investigating attitudes towards the use of mobile learning in higher education. Computers in Human Behavior, 56, 93-102. Retrieved from https://doi.org/10.1016/j.chb.2015.11.033
Brännback, M., Nikou, S., & Bouwman, H. (2016). Value systems and intentions to interact in social media: The digital natives. Retrieved from http://dx.doi.org/10.1016/j.tele.2016.08.018
Farley, H., Murphy, A., Johnson, C., Carter, B., Lane, M., Midgley, W., … Koronios, A. (2015). How do students use their mobile devices to support learning? A case study from an Australian regional university. Journal of Interactive Media in Education, 1(14), 1–13. doi: http://dx.doi.org/10.5334/jime.ar
Gikas, J., Grant, M. M. (2013). Mobile computing devices in higher education: Student perspectives on learning with cellphones, smartphones & social media. The Internet and Higher Education, 19, 18-26 Retrieved from https://doi.org/10.1016/j.iheduc.2013.06.002
Kong, S. C., & Song, Y., (2015). An experience of personalized learning hub initiative embedding BYOD for reflective engagement in higher education. Computers & Education, 88, 227–240. Retrieved from http://dx.doi.org/10.1016/j.compedu.2015.06.003
Parsons D. & Adhikari J. (2016). Bring your own device to secondary school: The perceptions of teachers, students and parents. The Electronic Journal of e-Learning, 14(1), 66-80. Retrieved from http://files.eric.ed.gov/fulltext/EJ1099110.pdf
Peffers, K., Tuunanen, T., Rothenberger, M. A., & Chatterjee, S. (2008) A design science research methodology for information systems research. Journal of Management Information Systems, 24(3), 45–77. doi:10.2753/MIS0742-1222240302
Wei, K. K., Teo, H. H., Chan, H. C., & Tan, B. C. Y. (2011). Conceptualizing and testing a social cognitive model of the digital divide. Information Systems Research, 22(1), 170-187. Retrieved from http://sites.gsu.edu/kwolfe5/files/2015/08/Digital-Divide-2edakv4.pdf






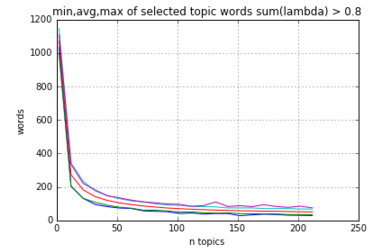
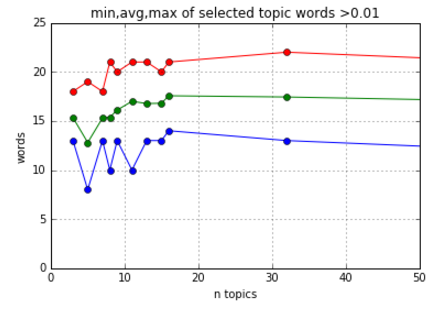
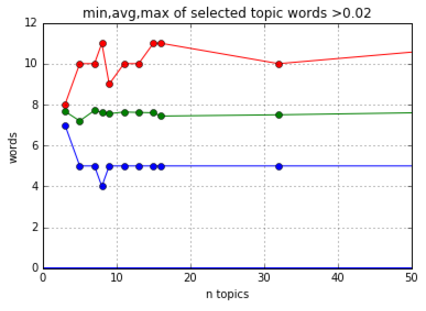
 Looking at the above, notice that after a point (150 topics), the number of words chosen levels out.
Looking at the above, notice that after a point (150 topics), the number of words chosen levels out.